11-1 什么是支撑向量机
支撑向量机的思想

图中是一个样本空间,里面有一些样本点,分成红色和蓝色两类。
逻辑回归是要找到一根决策边界,由决策边界把数据分成两类。但可能存在这样一些数据(下图),可能存在多条决策边界。(不适定问题)
 逻辑回归定义了一个损失函数,通过最小化损失函数求出决策边界。
假设逻辑回归算法最后求出的是这样一根直线(下图),它在前面的所给的样本空间中表现很好,但新来这样一个样本,那么很有可能它的分类结果是错误的。
逻辑回归定义了一个损失函数,通过最小化损失函数求出决策边界。
假设逻辑回归算法最后求出的是这样一根直线(下图),它在前面的所给的样本空间中表现很好,但新来这样一个样本,那么很有可能它的分类结果是错误的。
 这根决策边界的泛化效果不够好,因为它离红色样本点太近了。那么怎样的决策边界泛化能力比较好呢?
看上去下图这根直线的泛化能力要更好一点。
这根决策边界的泛化效果不够好,因为它离红色样本点太近了。那么怎样的决策边界泛化能力比较好呢?
看上去下图这根直线的泛化能力要更好一点。
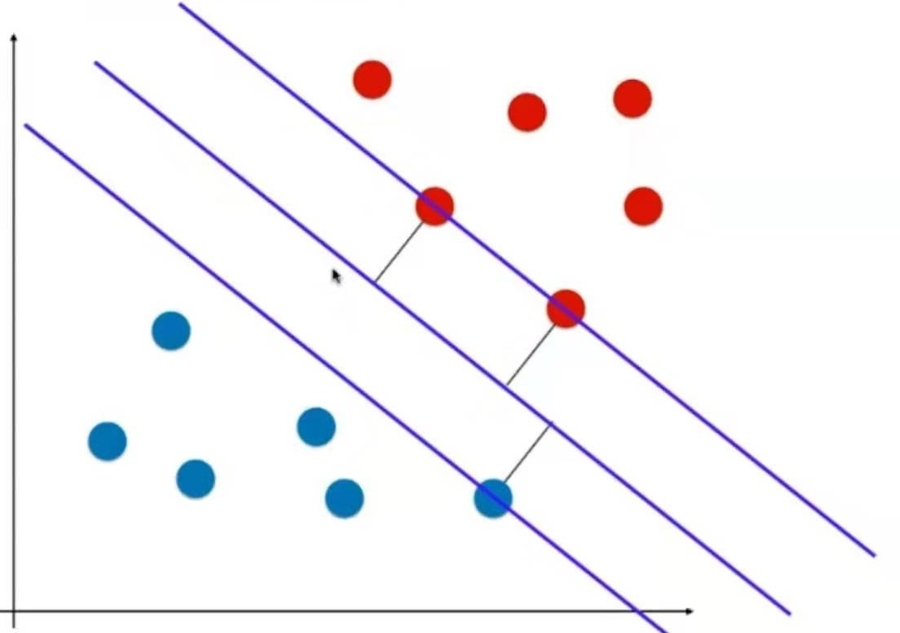
 离这根直线最近的点有3个,让这3个点离这根直线的距离尽可能地远。
也就是说,让这个决策边界既离红线尽可能远,也离蓝点尽可能远。于是得到了上图这样的决策边界。
它不仅将训练数据划分开类,还期望它的泛化能力尽可能好。它把对泛化能力的考量直接放到了算法的内部。
离这根直线最近的点有3个,让这3个点离这根直线的距离尽可能地远。
也就是说,让这个决策边界既离红线尽可能远,也离蓝点尽可能远。于是得到了上图这样的决策边界。
它不仅将训练数据划分开类,还期望它的泛化能力尽可能好。它把对泛化能力的考量直接放到了算法的内部。
把以上的思考用数学方式表达出来就是,让离决策边界最近的三个点,到决策边界的距离应该是一样的并且尽可能地大。
基于这三个点又找两根与决策边界平行的直线。这两根直线定义了一个区域。这个区域中不再有任何点。
什么是支撑向量机
SVM尝试寻找一个最优的决策边界。
这个决策边界距离两个类别的最近的样本最远。
这三个最近的样本称为支撑向量。
支撑向定义了一个区域,这个区域又定义了最优决策边界。
上下两根直线离决策边界的距离都是d。
上下两根直线之间的距离称为margin.
SVM要最大化margin  SVM只能解决线性可分的问题,即hard Margin SVM. 对hard Margin SVM改进,能解决线性不可分的数据,即soft Margin SVM
SVM只能解决线性可分的问题,即hard Margin SVM. 对hard Margin SVM改进,能解决线性不可分的数据,即soft Margin SVM
Last updated