10-8 多分类问题中的混淆矩阵
加载手写数据集
import numpy as np
from sklearn import datasets
digits = datasets.load_digits()
X = digits.data
y = digits.target
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.8,random_state=666)使用逻辑回归训练模型
from sklearn.linear_model import LogisticRegression
log_reg = LogisticRegression()
log_reg.fit(X_train, y_train)
log_reg.score(X_test, y_test)计算精准率
会报错,因为默认只能为二分类问题计算精准率
解决方法: 
计算混淆矩阵并可视化
计算混淆矩阵
输出: 
可视化
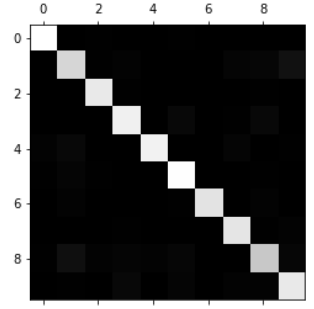

 图中越亮的地方表示犯错越多的地方。
针对错误比较多的地方做算法的微调。
图中越亮的地方表示犯错越多的地方。
针对错误比较多的地方做算法的微调。
Last updated