7-6 scikit learn中的PCA
from sklearn.decomposition import PCA
pca = PCA(n_components=1)
pca.fit(X)X_reduction = pca.transform(X)
X_restore = pca.inverse_transform(X_reduction)
plt.scatter(X[:, 0], X[:, 1], color='b', alpha=0.5)
plt.scatter(X_restore[:, 0], X_restore[:, 1], color='r', alpha=0.5)
plt.show()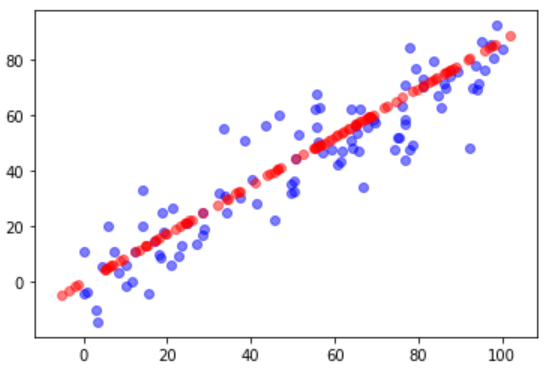
使用真实数据测试PCA降维对效率和准确度的影响
真实数据
几种降维结果比较
选择合适的降维效果
输出结果:

输出结果:  这张图表示了前N个维度所占方差的百分比
这张图表示了前N个维度所占方差的百分比
对原始数据降至2维的结果也有一定参考意义

Last updated