5-8 实现多元线性回归
Linear Regression
import numpy as np
from sklearn.metrics import r2_score
class LinearRegression:
def __init__(self):
"""初始化Linear Regression模型"""
self.coef_ = None
self.interception_ = None
self._theta = None
def fit_normal(self, X_train, y_train):
"""根据训练数据集X_train, y_train训练Linear Regression模型"""
assert X_train.shape[0] == y_train.shape[0], "the size of X_train must be equal to the size of y_train"
X_b = np.hstack([np.ones((len(X_train), 1)), X_train])
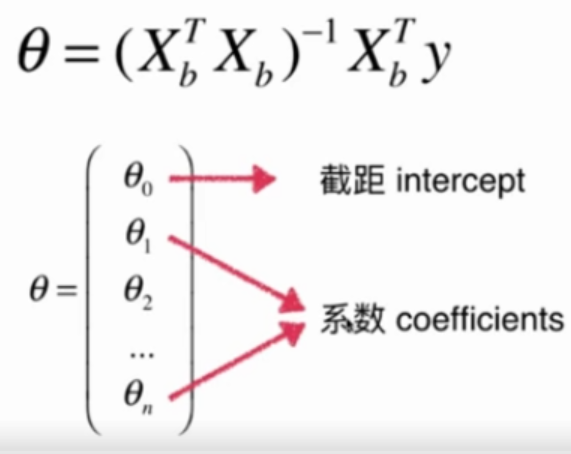
self._theta = np.linalg.inv(X_b.T.dot(X_b)).dot(X_b.T).dot(y_train)
self.interception_ = self._theta[0]
self.coef_ = self._theta[1:]
return self
def predict(self, X_predict):
"""给定待预测数据集X_predict,返回表示X_predict的结果向量"""
assert self.interception_ is not None and self.coef_ is not None, "must fit before predict"
assert X_predict.shape[1] == len(self.coef_), "the feature number of X_predict must equal to X_train"
X_b = np.hstack([np.ones((len(X_predict), 1)), X_predict])
return X_b.dot(self._theta)
def score(self, X_test, y_test):
"""根据测试数据集X_test, y_test确定当前模型的准确度"""
y_predict = self.predict(X_test)
return r2_score(y_test, y_predict)
def __repr__(self):
return "LinearRegression()"boston data
训练模型与预测结果
Last updated