4-2
代码实现KNN算法
import numpy as np
from math import sqrt
from collections import Counter
def kNN_classify(k, X_train, y_train, x):
assert 1 <= k <= X_train.shape[0], "k must be valid"
assert X_train.shape[0] == y_train.shape[0], "the size of X_train must equal to the size of y_train"
assert X_train.shape[1] == x.shape[0], "the feature number of x must be equal to X_train"
distances = [sqrt(np.sum((x_train-x)**2)) for x_train in X_train]
nearst = np.argsort(distances)
topK_y = [y_train[i] for i in nearst[:k]]
votes = Counter(topK_y)
return votes.most_common(1)[0][0]准备数据
调用算法
什么是机器学习
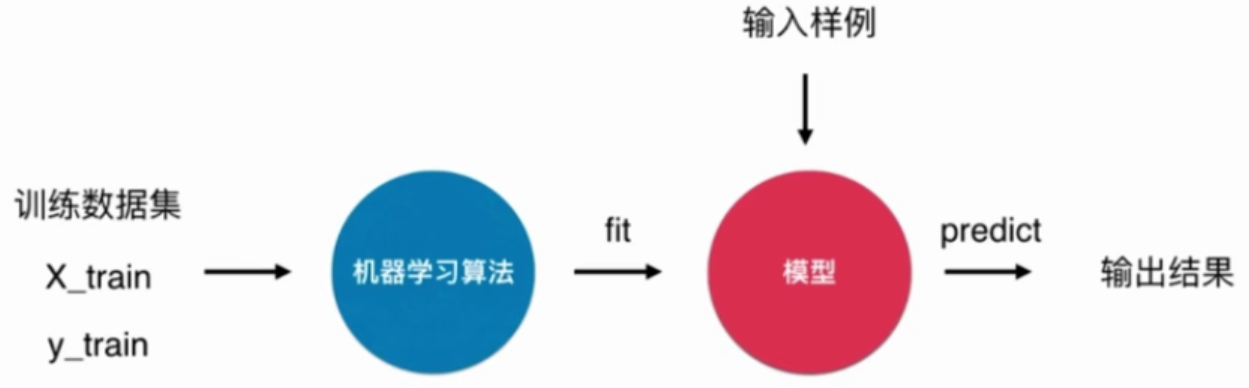
使用scikit-learn中的kNN
错误写法
这样写会报错:
 原因是,predict为了兼容多组测试数据的场景,要求参数是个矩阵
原因是,predict为了兼容多组测试数据的场景,要求参数是个矩阵
正确写法
重新整理我们的kNN的代码
封装成sklearn风格的类
使用kNNClassifier
Last updated